What Is Observability?
According to Wikipedia, “observability is the measure of how well internal states of a system can be inferred from knowledge of its external outputs.”
Think of it in terms of a patient receiving routine medical care after experiencing a nagging pain.
From an IT perspective, the goal of observability is to analyze external outputs—like symptoms—that provide windows into how the system is functioning internally. Observability examines effects and then correlates that to a specific cause.
Why has observability become such a hot concept in the IT world?
Since 2005, cloud computing—and the use of distributed apps—has exploded in popularity. Gone are the days when one could monitor a single cluster of VMs and call it a day.
In the modern IT world, an app might span multiple clouds, using containers and microservices. These services may be both distributed and multi-layered.
This is the key difference between the need for simple cloud native monitoring versus observability. Having a multi-tiered environment requires a holistic view of the overall infrastructure—a view that only observability can provide.
objective of observability
The objective of observability is to deliver a comprehensive view of infrastructure, more than what individual system monitoring can provide. It helps to determine the root cause of a problem with much more certainty, particularly in a distributed, complex system.
An observable system’s external outputs include metrics, events, Traces and logs. Some examples of how DevOps engineers can take advantage of observability include:
- Security anomaly detection
- Cost analysis of cloud resources
- Call trace analysis to determine how specific input values are impacting program failure
- Identification of seasonal spikes in system load and tying that back to a suboptimal load balancer
Most observability platforms provide the detailed information a user needs to easily identify the root cause of a problem. Some can also suggest fixes to the problem. A few platforms even take it a step further by performing the corrective measures themselves.
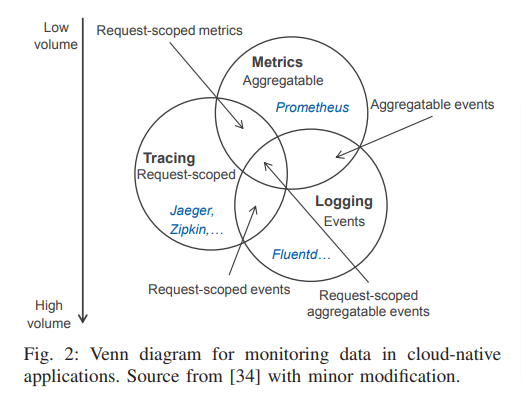
Difference between Metrics, Tracing and Logging

{kind=link}
observability platform
Analytics on top of Service Mesh
Reference List
- Kufel, Ł. (2016). Tools for distributed systems monitoring. Foundations of computing and decision sciences, 41(4), 237-260.
Reference List
- https://www.splunk.com/en_us/blog/learn/logs-vs-metrics.html
- https://www.sumologic.com/blog/logs-metrics-overview/
- https://logz.io/blog/logs-or-metrics/#:~:text=Metrics%20can%20be%20used%20to,variety%20of%20additional%20use%20cases.
- https://medium.com/@surfd1001/things-to-know-about-observability-mechanisms-a52876e421c7
- https://microsoft.github.io/code-with-engineering-playbook/observability/log-vs-metric-vs-trace/
- https://www.crowdstrike.com/cybersecurity-101/observability/observability-vs-monitoring/#:~:text=Monitoring%20tells%20you%20that%20something,problem%2C%20and%20locate%20the%20error.
- https://newrelic.com/blog/best-practices/what-is-cloud-native-observability