The most common metric for classification is accuracy, which is the fraction of samples predicted correctly as shown below:
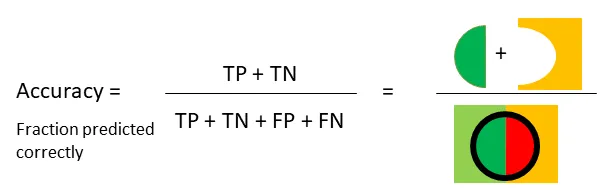 We can obtain the accuracy score from scikit-learn, which takes as inputs the actual labels and the predicted labels
We can obtain the accuracy score from scikit-learn, which takes as inputs the actual labels and the predicted labels
from sklearn.metrics import accuracy_score
accuracy_score(df.actual_label.values, df.predicted_RF.values)Using accuracy as a performance metric, the RF model is more accurate (0.67) than the LR model (0.62). So should we stop here and say RF model is the best model? No! Accuracy is not always the best metric to use to assess classification models. For example, let’s say that we are trying to predict something that only happens 1 out of 100 times. We could build a model that gets 99% accuracy by saying the event never happened. However, we catch 0% of the events we care about. The 0% measure here is another performance metric known as recall.