Data Stream Processing Engines (DSPEs) lie at the core of DSPSs and enable the definition and execution of stream processing pipelines.
Use case
Under several application scenarios such as
- fraud detection in financial transactions
- healthcare analytics involving digital sensors
- Internet of Things (IoT)
MOTIVATION
Modern Data Stream Processing Systems (DSPS) try to combine batch and stream processing capabilities into a single or multiple parallel data processing pipelines.
ARCHITECTURE OF A DSPS
the architecture of a DSPS is generally multi-tiered and is composed of many loosely coupled components that include data sources, data collection systems, data storage systems, messaging systems, and stream processing and delivery systems.
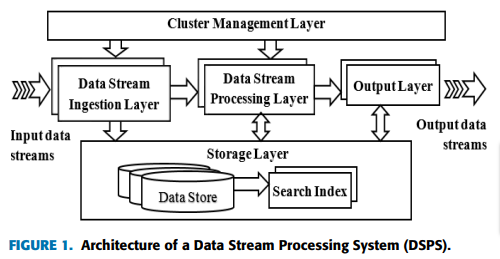
data stream ingestion layer
Data ingestion is the process of getting data streams from its source to its processing or storage system.
There are many sources of input data streams [28]. These include data streams from various IoT devices such as sensors, video and other electronic monitors, social network Application Programming Interfaces (APIs), WebSockets, Representational State Transfer (RESTful) Web services, service usage logs, other stream processing systems, or any object which can collect and transmit time-sensitive data.
Queueing systems encompass the spectrum of messaging services, from the traditional message queuing products such as MQTT, RabbitMQ, and ActiveMQ to the newer products such as NSQ and ZeroMQ [9], [29]. Apache Kafka and DistributedLog have grown to embody more than a message system, and both currently support publishing and subscribing to streams of records [8]. There are also many commercial stream ingestion systems including Scribe [26] developed at Facebook, Kinesis Data Firehose managed by Amazon Web Services (AWS), IBM WebSphere MQ and Messaging services on Azure [29]. Message Queue
data stream processing layer
The data stream processing layer is where the streaming data processing applications or jobs are executed. It can host loosely coupled disjoint applications or a DSPE or both. DSPEs generally offer a set of streaming data processing operators which can be configured and threaded together to build a stream data processing pipeline to analyze incoming data streams [30].
data stream processing engines (DSPEs)
storage layer
DSPSs often store analyzed data, discovered patterns and extracted knowledge from different data processing stages for further processing.
DSPS architecture ranges from traditional file systems such as HDFS and Baidu File System (BFS) to distributed file relational databases such as PostgreSQL, key-value stores such as Redis, in-memory databases such as VoltDB, document storage such as MongoDB, graph storage systems such as Neo4j, NoSQL databases such as Cassandra, and NewSQL such as CockroachDB [38].
resource management layer
The resource management layer coordinates actions among compute and storage nodes and manages resource allocation and scheduling in distributed systems to enable parallel processing of high volume and velocity of data streams [39].
Data Stream Output Layer
The results from data stream processing pipelines can be directed to an application, another workflow, a data visualization tool, or an alert or monitoring dashboard [8].
Reference List
- Isah, H., Abughofa, T., Mahfuz, S., Ajerla, D., Zulkernine, F., & Khan, S. (2019). A survey of distributed data stream processing frameworks. IEEE Access, 7, 154300-154316.